1. 基本
この章では、関数型言語とオブジェクト指向を 理解するのに必要となる、基本の概念と用語を説明します。 すでに分かっている人であれば、 読み飛ばしてもかまいません。
1.1. 関数型言語
1.1.1. 評価
人間:「3と4を足すといくつ?]
計算機:「7です]計算機(computer)は 人間からの質問(question)に対して答え(answer)を返します。

この処理を関数型言語では評価(evaluation)と呼び、 人間から受ける質問の事を文(statemennt)、 そして人間へ返す答えの事を作用(effect)と呼びます。

ここで、文は式(expression)と宣言(declaration)の二つに分類され、 作用は値(value)と環境(environment)の二つに分類されます。
<評価(evaluation)> ::= <文> <作用> .
<文(statement)> ::= <式> | <宣言> .
<作用(effect)> ::= <値> | <環境> .以下の実行例であれば、
「式 3 + 4 を評価した結果は値 7 である」
と解釈します。
umu:1> 3 + 4
val it : Int = 71.1.2. 式と定数
式(expression)は多くの要素から構成される文の一種であり、 値(value)もまた多くの要素から構成される作用の一種です。
<式(expression)> ::=
<定数>
| <変数>
| <適用式>
| <ラムダ式>
| <分岐式>
/* | .... etc */ .
<値(value)> ::=
<整数>
| <小数>
| <文字列>
| <シンボル>
| <関数閉包>
/* | .... etc */ .その中から、最も単純な定数(constant)と演算子(operator)について 評価の方法を以下に示します。
-
定数: [例]
3-
定数が表す値を返します。
-
-
演算子: [例]
+-
まずその被演算子(operand)を再帰的に評価し、
-
その値を元に演算して結果の値を返します。
-

以下の実行例では、
-
整数を表す定数
3、 -
文字列を表す定数
"Apple"そして -
シンボルを表す定数
@Banana
を評価しています。
umu:1> 3
val it : Int = 3
umu:2> "Apple"
val it : String = "Apple"
umu:3> @Banana
val it : Symbol = @Symbol
umu:4>1.1.3. 変数と環境
値には名前を付けることができます。
たとえば円周率を表すのに
毎回 3.14159265358979 と書くのは
面倒ですからそれを PI と命名し、
その名前で円周率の値を表すものと解釈します。
ここで、
-
値に付けられた名前の事を変数(variable)、
-
名前と値との対応関係を束縛(binding)、
-
束縛が記録される辞書の事を環境(environment)
と呼びます。
<環境(environment)> ::= { <束縛> } .
<束縛(binding)> ::= <変数> <値> .
<変数(variable)> ::= <名前> .また、
-
名前を付ける、すなわち名前と値との対応関係を生む行為を 「(名前に値を)束縛する(bind)」、
-
環境へ新たな束縛を追加する行為を「(環境を)拡張する(extend)」
と表現します。
変数は以下のように評価されます。
-
変数の名前を環境(environment)から探し(lookup)、
-
もし見つかれば束縛された値を返し、
-
見つからなければエラーとします。
-
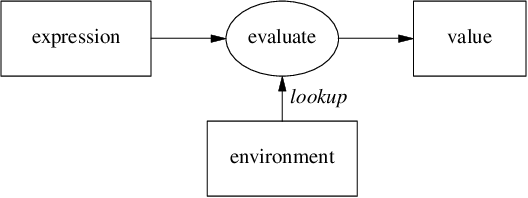
以下の実行例では、
-
真の論理値を表す標準変数
TRUEと -
円周率を表す標準変数
PI -
足し算関数を表す標準変数
(+)
を評価しています。また存在しない変数 foo では評価が失敗しています。
umu:1> TRUE
val it : Bool = TRUE
umu:2> Umu::Math::PI
val it : Float = 3.141592653589793
umu:3> (+)
fun it = #<+: { x : Number y : Number -> (x).(+ y) }>
umu:4> foo
[NameError] Unbound value identifier: 'foo' -- #4 in "<stdin>"
umu:5>1.1.4. 宣言と環境
宣言(declaration)は多くの要素から構成される文の一種であり、 変数と式から構成され、 現在の環境(environment)を新しい束縛で拡張します。
<宣言(declaration)> ::=
<val宣言>
| <fun宣言>
| <import宣言>
/* | .... etc */ .
<val宣言(value declaration)> ::= <変数> <式> .宣言は以下のように評価されます。
-
現在の環境の下で再帰的に式を評価し、
-
評価した値を変数に束縛し、
-
その束縛で現在の環境を拡張(extend)し、
-
次回の評価では拡張された新しい環境を参照します。
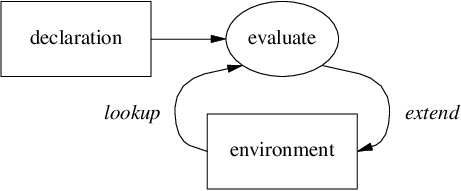
以下の実行例では、
-
まず変数
xとyを宣言し、 -
その環境の下で式
x + yを評価し、 -
その評価した値で変数
zを宣言しています。
umu:1> val x = 3 # 変数 x を宣言
val x : Int = 3
umu:2> val y = 4 # 変数 y を宣言
val y : Int = 4
umu:3> val z = x + y # 式 x + y を評価し、変数 z を宣言
val z : Int = 7
umu:4>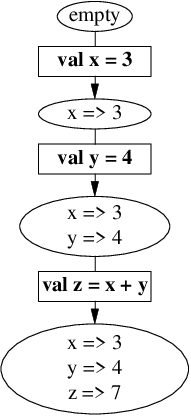
1.1.5. 関数とカリー化
式 3 + 4 の中で、記号 + は演算子(operator)と呼ばれ、
数値 3 と 4 は被演算子(operand)と呼ばれます。
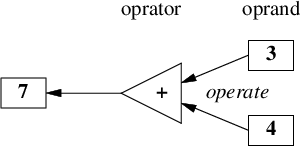
関数型言語では、
-
この演算子を一般化して関数(function)、
-
演算子の振る舞いを適用(application)、
-
式
(+) 3 4を適用式(application expression)
と呼び、適用式 (+) 3 4 を
-
「
3と4を関数(+)に適用する(apply)」
と表現します。
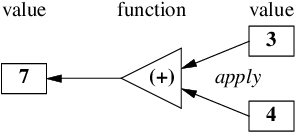
ここで適用式 () 3 4` では、
関数 `() へ2つの引数を渡しているように見えますが、
実際には関数 (+) は1引数として定義されており、
以下のように解釈されます。
-
値
3を関数()` へ適用すると、関数 `#<>が返る。 -
値
4を返ってきた関数#<+>へ適用すると、値7が返る。
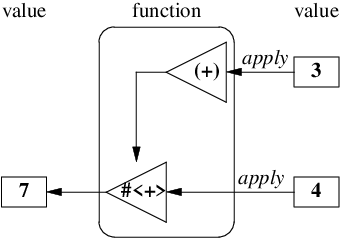
こうした多引数関数を単一引数関数の複合体として定義するスタイルは、 近年のモダンな関数型言語の特徴の一つであり、 単一引数に分解された関数は「カリー化(curryed)された」と呼ばれます。
また、関数が返す値 #<+> を関数閉包(function closure)
あるいはクロージャと呼びます。
以下の実行例では、
-
まず単純に式
3 + 4を評価して結果が値7である事を確認し、 -
続いて足し算関数を表す変数
(+)を評価し、 -
その評価した値である関数閉包
#<+>に値3を適用し、 -
その適用の結果である関数閉包
#<+>に値4を適用して -
結果が値
7であることを確認しています。
umu:1> 3 + 4
val it : Int = 7
umu:2> (+)
fun it = #<+: { x : Number y : Number -> (x).(+ y) }>
umu:3> it 3
fun it = #<+: { y : Number -> (x).(+ y) }>
umu:4> it 4
val it : Int = 7
umu:5>1.1.6. 関数宣言、ラムダ式そして適用式
関数を定義(definition)するには、宣言 fun を用います。
宣言 fun は関数の名前と関数を定義する式から構成されており、
その定義式をラムダ式(lambda expression)と呼びます。
<fun 宣言(function declaration)> ::= <関数名> <ラムダ式> .
<関数名(function name)> ::= <変数> .ラムダ式は
-
1つかそれ以上の仮引数(formal parameter, または parameter)の並びと
-
本体式(body expression)
から構成され、それぞれ仮引数は変数、本体式は式の別名です。
<ラムダ式(lambda expression)> ::=
<仮引数(1)> { <仮引数(n)> } <本体式> .
<仮引数(formal parameter)> ::= <変数> .
<本体式(body expression)> ::= <式> .ラムダ式を評価した結果が関数閉包(function closure)と呼ばれる値であり、
-
ラムダ式それ自身と
-
ラムダ式を評価した時点の環境
から構成されます。
<関数閉包(function closure)> ::= <ラムダ式> <環境> .ラムダ式が評価された時点だと、 その本体式は環境とともに関数閉包の内部に閉じ込められ、 計算を停止しているという状況に注意してください。 この計算の停止は、 (以降で説明する)関数閉包に実引数を適用するまで続きます。
そして、適用式は
-
ただ1つの演算子式(operator expression)と
-
1つかそれ以上の被演算子式(operand expression)の並び
から構成され、演算子式と被演算子式はどちらも式の別名です。
<適用式(application language)> ::=
<演算子式> <被演算子式(1)> { <被演算子式(n)> } .
<演算子式(operator expression)> ::= <式> .
<被演算子式(operand expression)> ::= <式> .適用式は以下のように評価されます。
-
被演算子式(1 .. n)の各々について
-
現在の環境下で被演算子式の並びを評価し、
-
その結果の値を「実引数(actual parameter または argument)の並び」と 呼ぶものとし、
-
-
現在の環境下で演算子式を評価し、
-
もし演算子式を評価した値が関数閉包(クロージャ)であれば、
-
実引数(1 .. n)の各々と関数閉包の仮引数(1 .. n)の各々について
-
実引数の値を仮引数の変数に束縛し、
-
-
その束縛セットで(閉じ込められていた)関数閉包の環境を拡張し、
-
その新しい環境の下で、 (閉じ込められていた)関数閉包の本体式を再帰的に評価する。
-
-
もし関数でなければエラーとして扱う。
-
以下の実行例では、
-
すでに変数
x,y,zが存在する環境下において、 -
関数
addを宣言し、 -
数
30と40を関数addに適用し、 -
その結果を元に変数
zを宣言しています。
umu:4> fun add = x y -> x + y
fun add = #<add: { x y -> (+ x y) }>
umu:5> val z = add 30 40
val z : Int = 70
umu:6>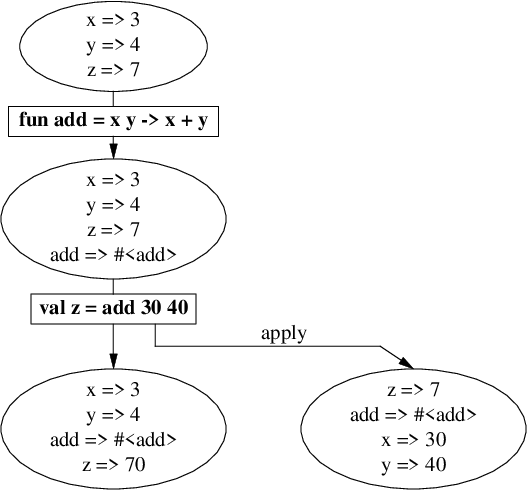
前提とする環境に応じて変数の値は変わります。たとえば
-
変数
xは3あるいは30 -
変数
zは7あるいは70です。
自然語で周囲の状況(あるいは空気)に応じて言葉の意味が変わるのと似ています。 この性質から、環境の事を文脈(context)と呼ぶことがあります。
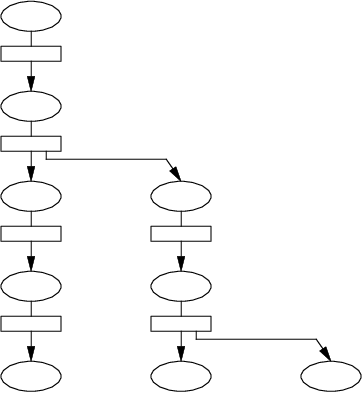
また環境が枝分かれした先で起こる変化は、枝の元に影響を及ぼしません。
たとえば枝の先で変数 x は値 30 に変化しますが、
枝分かれの元では 3 のままです。
そして環境の枝分かれは適用式を評価するたびに発生し、環境をノードとする 階層的なツリーが作られることになります。
1.1.7. 再帰関数と相互再帰 (empty)
1.1.8. データ型と値 (empty)
1.2. オブジェクト指向
1.2.1. オブジェクト指向パラダイム
人間:「3と4を足すといくつ?]
計算機:「7です]この計算機との対話を関数型言語では、
-
値
3と4を関数(+)に適用(apply)すると値7が返る
と解釈すると説明してきました。
関数型パラダイムにおいて計算の主役は関数(function)であり、 3や4といった値(value)は脇役です。
これに対してオブジェクト指向パラダイムでは、
-
関数
-
3や4といった値、
これらすべてを平等に計算の主役であると考えてオブジェクト(object)と呼び、
-
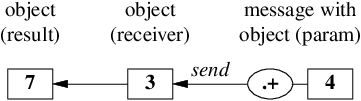
オブジェクト
3にメッセージ.+ 4を送信(send)すると オブジェクト7が返る、
あるいはメッセージを受信するオブジェクトの視点で、
-
オブジェクト
3はメッセージ.+ 4を受信(receive)すると オブジェクト7を返す
と解釈し、送信式 3.+ 4 で表現します。
オブジェクトはメッセージの種類に応じて適切に振る舞うことができます。
たとえば整数オブジェクト 3 は、
-
メッセージ
.* 4に対して整数オブジェクト12を返し、 -
メッセージ
.odd?に対して論理値オブジェクトTRUEを返し、 -
メッセージ
.showに対して文字列オブジェクト"3"を返します。
また関数もまたオブジェクトですから、関数オブジェクト (+) は
適用メッセージ .apply-binary 3 4 に対して整数オブジェクト 7 を返します。
これは、関数への適用をメッセージの送信で模倣していると見なすことができます。
umu:1> 3 + 4
val it : Int = 7
umu:2> 3 * 4
val it : Int = 12
umu:3> 3.odd?
val it : Bool = TRUE
umu:4> 3.show
val it : String = "3"
umu:5> (+).apply-binary 3 4
val it : Int = 7
umu:6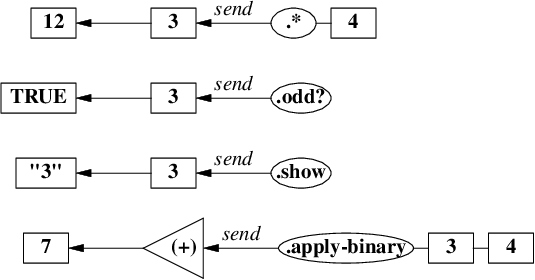
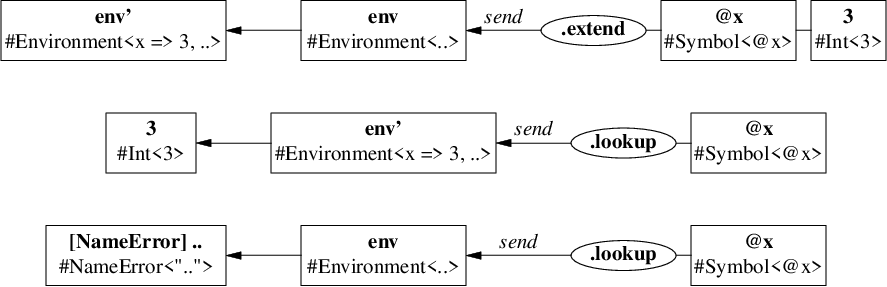
他にも式(expression)や宣言(declaration)をオブジェクトであると見なせば、
-
式オブジェクト
3 + 4は評価メッセージ.evaluate envに対して 値オブジェクト7を返し、 -
宣言オブジェクト
val x = 3は評価メッセージ.evaluate envに対して、 現在の環境envを束縛x ⇒ 3で拡張した 新しい環境オブジェクトenv'を返します。

更に環境(environment)もオブジェクトであると見なせば、環境オブジェクトは
-
拡張メッセージ
.extend @x 3に対して 束縛x ⇒ 3で拡張された新しい環境オブジェクトenv'を返し、 -
検索メッセージ
.lookup @xに対して-
見つかれば整数オブジェクト
3を返し、 -
見つからなければ例外
NameErrorを起動します。
-
以下の実行例では、
-
インタプリタを起動した直後の環境下で変数
xを評価すると、 例外NameErrorが発生することを確認した後、 -
変数
xを宣言し、 -
この環境下で再び変数
xを評価すると、 今度は値3が返ることを確認しています。
umu:1> x
[NameError] Unbound value identifier: 'x' -- #1 in "<stdin>"
umu:2> val x = 3
val x : Int = 3
umu:3> x
val it : Int = 3
umu:4>1.2.2. メッセージとカリー化
オブジェクトへ送信するメッセージについて与える引数の個数に着目すると、
-
単項メッセージ(unary message): 引数は無し(メッセージセレクタのみ)
-
[例] Int#odd? : Bool
-
[例] Int#show : String
-
-
二項メッセージ(binary message): 引数は1個のみ
-
[例] Int#+ : Int → Int
-
[例] Int#* : Int → Int
-
[例] Expression#evaluate : Environment → Value
-
[例] Declaration#evaluate : Environment → Environment
-
[例] Environment#lookup : Symbol → Value
-
-
多項メッセージ(n-ary message): 引数は2個かそれ以上
-
[例] Fun#apply-binary : Top → Top → Top
-
[例] Environment#extend : Symbol → Value → Environment
-
[例] Environment#apply-binary : Top → Top → Top
-
にの三つに分類されます。
ここで、すべての関数が単一引数関数の複合体として定義され、 そうしたスタイルがカリー化と呼ばれていたことを思い出してください。 メッセージも同じく、
-
すべてのメッセージは単項メッセージとその複合体によって定義され、
二項メッセージを使う送信式 3.+ 4 は、以下のように解釈されます。
-
整数オブジェクト
3へメッセージ.` を送信(send)すると、 関数オブジェクト(= 関数閉包 or クロージャ) `#<: ..>が返る。 -
返ってきた 関数オブジェクトに整数オブジェクト
4を適用(apply)すると、 整数オブジェクト7が返る。
umu:1> 3.+ 4
val it : Int = 7
umu:2> 3.+
fun it = #<{ %x_1 -> (%r).(+ %x_1) }>
umu:3> it 4
val it : Int = 7
umu:4>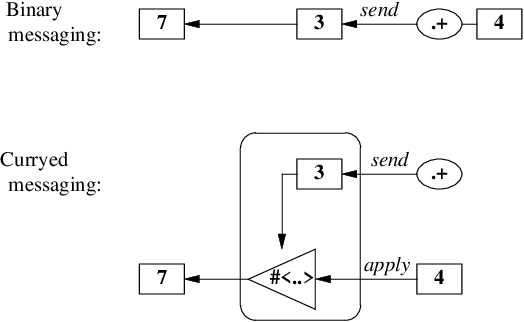
多項メッセージも同じように解釈します。
umu:1> (+).apply-binary 3 4
val it : Int = 7
umu:2> (+).apply-binary
fun it = #<{ %x_1 %x_2 -> (%r).(apply-binary %x_1 %x_2) }>
umu:3> it 3
fun it = #<{ %x_2 -> (%r).(apply-binary %x_1 %x_2) }>
umu:4> it 4
val it : Int = 7
umu:5>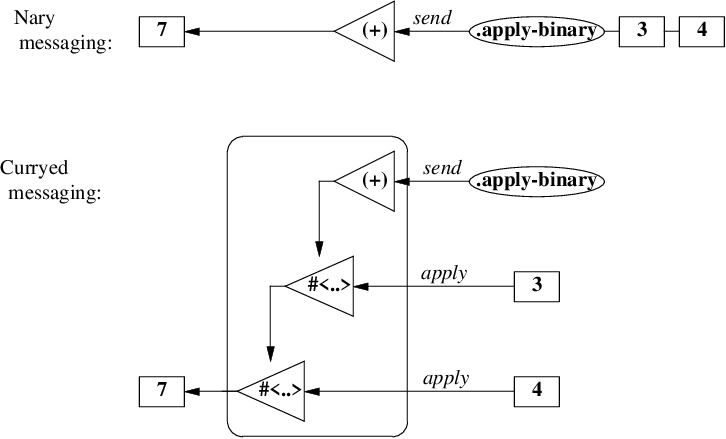
1.2.3. 送信式とメッセージ
オブジェクトにメッセージを送信する送信式(send expression)は式の一種であり、 レシーバ式と1つかそれ以上のメッセージの並びから構成され、 レシーバ式は式の別名です。
<送信式(send expression)> ::=
<レシーバ式>
<メッセージ(1)> { <メッセージ(n)> } .
<レシーバ式(receiver expression)> ::= <式> .またメッセージはメッセージセレクタとメッセージ引数の並びから構成され、
メッセージセレクタは文字 '.' で始まるトークンであり、
メッセージ引数は式の別名です。
<メッセージ(message)> ::=
<メッセージセレクタ>
<メッセージ引数(1)> { <メッセージ引数(n)> } .
<メッセージ引数(message parameter)> ::= <式> .ここで、オブジェクトは内部に
-
受信したメッセージに応じた適切な振る舞いの定義、および
-
メッセージセレクタとキーとして振る舞い定義への対応が記録された辞書
を持ち、
-
メッセージに応じた振る舞いの定義をメソッド(method)、
-
メッセージセレクタとメソッドの対応が記録された辞書を メソッドテーブル(method table)
と呼びます。
送信式は以下のように評価されます。
-
レシーバ式を評価しレジーバオブジェクトを得て、
-
メッセージ(1..n)の各々について
-
当該メッセージ引数の並びを評価し、
-
レシーバオブジェクトのメソッドテーブルから 当該メッセージセレクタを検索し、
-
もし見つかれば
-
メッセージセレクタに対応するメソッドを取得し、
-
取得したメソッドに評価したメッセージ引数の並びを与えて 呼び出し(invoke)、
-
メソッドが返したオブジェクトを次回のレシーバとする。
-
-
もし見つからなければ
-
未知のメッセージには応答できない旨のエラーとして扱う。
-
-
-
1.2.4. クラスとインスタンス
オブジェクト 3 はメッセージ .+ 4 に対して 7 を返し、
同様にオブジェクト 4 はメッセージ .+ 4 に対して 8 を返します。
こうした振る舞いの類似したオブジェクトの集まりをクラス(class)と呼び、
3 や 4 などのオブジェクトをインスタンス(instance)と呼びます。
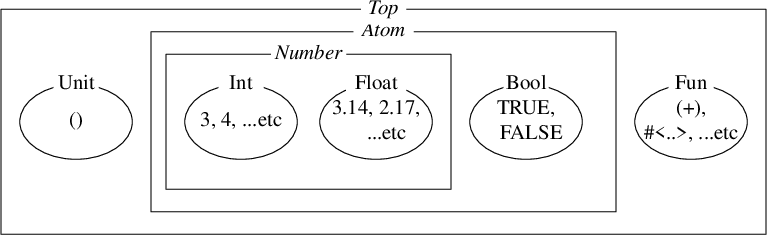
素朴な集合論であれば、
-
インスタンス
3や4は要素(element)、そして -
整数クラス
Intは部分集合(subset)であり、
その全体集合をクラス Top と呼びます。
以下に、この集合の構造をベン図で示します。

1.2.5. 抽象クラスと具象クラス
オブジェクトには整数 3 や 4 だけでなく、
3.14 や 2.17 といった小数も存在し、小数クラス Float に所属します。
小数クラスのオブジェクトは整数クラスのオブジェクトと同様、
メッセージ .+ や .* などに対して適切に振る舞うことが可能です。
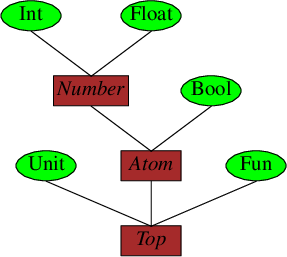
この振る舞いの類似したクラスの集まりをスーパークラス(superclass)と呼び、
下位のクラスをサブクラス(subclass)と呼びます。
また一般的に、こうした下位の概念から上位の概念を導く事は
抽象化(abstraction)と呼ばれています。
集合論であれば、たとえば
-
整数クラス
Intや小数クラスFloatはサブクラス、 すなわち部分集合(subset)であり、そして -
数クラス
Numberはスーパークラス、 すなわち親集合(superset)であり、 -
これらのクラスは入れ子集合(nested set)を形成します。
以下に入れ子集合の一例について、その構造をベン図で示します。
またサブクラスの集まりからスーパークラスを導くボトムアップな視点とは逆に、 あるクラスに着目し更に分類を細分化していくつかのサブクラスを導くという トップダウンな視点もあります。このケースを継承(inheritance)と呼びます。
ここで責務に着目すると、クラスは以下の二つに分類されます。
-
抽象クラス(abstract class)
-
[責務] クラス継承により生ずる抽象化
-
[特徴]
-
サブクラスを持つ、すなわち部分集合(subset)を持つ
-
直下にインスタンス、すなわち要素(element)は持たない
-
-
[例] Top, Atom, Number
-
-
具象クラス(concrete class)
-
[責務] クラスの具体化、いわゆるインスタンスの生成
-
[特徴]
-
インスタンスを持つ、すなわち要素(element)を持つ
-
サブクラス、すなわち部分集合(subset)は持たない
-
-
[例] Int, Float, Bool, Fun
-
入れ子集合を樹(ツリー)に見立てれば、
-
幹や枝が抽象クラス
-
末端の葉っぱが具象クラス
になります。
実際のクラス階層は REPL のサブコマンド :class で確認できます。
実行例を以下に示します。
クラス名の末尾が文字 / であれば抽象クラス、さもなければ具象クラスです。
umu:1> :class
Top/
Class
Device
Object/
Atom/
Bool
Number/
Float
Int
String
Symbol
Dir
Fun
IO/
Input
Output
:
:
:
umu:2>1.3. 作用と副作用
文を評価した時、作用(effect)だけでなく別の結果が生じることがあります。 この副次的に発生する結果を副作用(side effect)と呼びます。
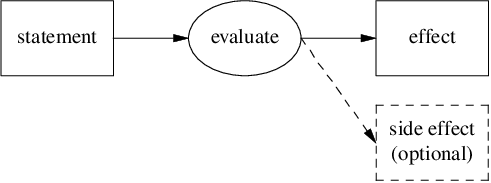
副作用は以下の三つに分類されます。
-
乱数発生
-
入出力
-
破壊的代入
-
リファレンス
-
S-式
-
2. アトム
2.1. 整数
umu:1> 3
val it : Int = 3
umu:2> 3 + 4
val it : Int = 7
umu:3>2.2. 小数
umu:1> 3.0
val it : Float = 3.0
umu:2> 3.0 + 4.0
val it : Float = 7.0
umu:3>2.3. 文字列
umu:1> "Hello"
val it : String = "Hello"
umu:2> "Hello" ^ " world"
val it : String = "Hello world"
umu:3>2.4. シンボル
umu:1> @hello
val it : Symbol = @hello
umu:2> to-s @hello
val it : String = "hello"
umu:3> show @hello
val it : String = "@hello"
umu:4>2.5. 論理値
umu:1> TRUE
val it : Bool = TRUE
umu:2> 3 == 3
val it : Bool = TRUE
umu:3> 3 == 4
val it : Bool = FALSE
umu:4>3. 直積(未)
3.1. タプル
3.2. 名前付きタプル
4. 直和(未)
4.1. オプション
4.2. リザルト
4.3. タグ付きデータ
5. リスト(未)
6. インターバル
インターバル(interval, 間隔)は整数の列を表現するオブジェクトです。 リストと似ていますが、以下に示す違いがあります。
-
リストの要素は任意のオブジェクトですが、インターバルの要素は整数に限られます。
-
インターバルは以下の3つの属性だけから構成されているので、長い列ではメモリ効率が優れています。
-
current: 現在値
-
stop: 停止値
-
step: 間隔値
-
-
インターバルは単なるデータ表現だけでなく、反復制御に用いることができます。たとえば、
-
C言語の
for (i = 1 ; i ⇐ 10 ; i++) { … }という手続き型のループ処理は、 -
インターバルを使って
[1 .. 10].for-each { i → … }と書きます。
-
6.1. インターバルオブジェクトの生成
6.1.1. (1) インターバル式で
umu:1> [1 .. 10]
val it : Interval = [1 .. 10 (+1)]
umu:2> [1, 3 .. 10]
val it : Interval = [1 .. 10 (+2)]
umu:3> it.contents
val it : Named = (current:1 stop:10 step:2)
umu:4>6.1.2. (2) インスタンスオブジェクトへの送信式で
6.1.2.1. (2-1) 二項インスタンスメッセージ
二項インスタンスメッセージ Int#to : Int → Interval を送信
umu:1> 1.to 10
val it : Interval = [1 .. 10 (+1)]
umu:2> 1.to
fun it = #<{ %x_1 -> (%r).(to %x_1) }>
umu:3> it 10
val it : Interval = [1 .. 10 (+1)]
umu:4>多項インスタンスメッセージ Int#to-by : Int → Int → Interval を送信
umu:1> 1.to-by 10 2
val it : Interval = [1 .. 10 (+2)]
umu:2> 1.to-by
fun it = #<{ %x_1 %x_2 -> (%r).(to-by %x_1 %x_2) }>
umu:3> it 10
fun it = #<{ %x_2 -> (%r).(to-by %x_1 %x_2) }>
umu:4> it 2
val it : Interval = [1 .. 10 (+2)]
umu:5>6.1.2.2. (2-2) キーワードインスタンスメッセージ
キーワードインスタンスメッセージ Int#(to:Int) → Interval と Int#(to:Int by:Int) → Interval を送信
umu:1> 1.(to:10)
val it : Interval = [1 .. 10 (+1)]
umu:2> 1.(to:10 by:2)
val it : Interval = [1 .. 10 (+2)]
umu:3>6.1.3. (3) クラスオブジェクトへの送信式で
6.1.3.1. (3-1) 単純クラスメッセージ
単純クラスメッセージ &Interval.make : Int → Int → Interval を送信
umu:1> &Interval.make 1 10
val it : Interval = [1 .. 10 (+1)]
umu:2> &Interval.make
fun it = #<{ %x_1 %x_2 -> (%r).(make %x_1 %x_2) }>
umu:3> it 1
fun it = #<{ %x_2 -> (%r).(make %x_1 %x_2) }>
umu:4> it 10
val it : Interval = [1 .. 10 (+1)]
umu:5>単純クラスメッセージ &Interval.make-by : Int → Int → Int → Interval を送信
umu:1> &Interval.make-by 1 10 2
val it : Interval = [1 .. 10 (+2)]
umu:2> &Interval.make-by
fun it = #<{ %x_1 %x_2 %x_3 -> (%r).(make-by %x_1 %x_2 %x_3) }>
umu:3> it 1
fun it = #<{ %x_2 %x_3 -> (%r).(make-by %x_1 %x_2 %x_3) }>
umu:4> it 10
fun it = #<{ %x_3 -> (%r).(make-by %x_1 %x_2 %x_3) }>
umu:5> it 2
val it : Interval = [1 .. 10 (+2)]
umu:6>6.1.3.2. (3-2) キーワードクラスメッセージ
キーワードクラスメッセージ &Interval.(from:Int to:Int) → Interval と
&Interval.(from:Int to:Int by:Int) → Interval を送信
umu:1> &Interval.(from:1 to:10)
val it : Interval = [1 .. 10 (+1)]
umu:2> &Interval.(from:1 to:10 by:2)
val it : Interval = [1 .. 10 (+2)]
umu:3>6.2. インターバルオブジェクトの操作
インターバルはリストと同じくモルフ(morph)と呼ばれるコレクションの一種ですから、 リストと同様なメッセージに応答できます。
umu:1> [1 .. 10].to-list
val it : Cons = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
umu:2> [1, 3 .. 10].to-list
val it : Cons = [1, 3, 5, 7, 9]
umu:3> [1 .. 10].select odd?
val it : Cons = [1, 3, 5, 7, 9]
umu:4> [1 .. 10].map to-s
val it : Cons = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
umu:5> [1 .. 10].select odd?.map to-s
val it : Cons = ["1", "3", "5", "7", "9"]
umu:6> [1 .. 3].for-each print
1
2
3
val it : Unit = ()
umu:7>7. リスト内包表記
umu:1> [|x| val x <- [1 .. 10]]
val it : Cons = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
umu:2> [|x| val x <- [1 .. 10] if odd? x]
val it : Cons = [1, 3, 5, 7, 9]
umu:3> [|to-s x| val x <- [1 .. 10] ]
val it : Cons = ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10"]
umu:4> [|to-s x| val x <- [1 .. 10] if odd? x]
val it : Cons = ["1", "3", "5", "7", "9"]umu:1> [|k, v| val k <- [@a, @b] val v <- [1 .. 3]]
val it : Cons = [(@a, 1), (@a, 2), (@a, 3), (@b, 1), (@b, 2), (@b, 3)]
umu:2> [|k: v:| val k <- [@a, @b] val v <- [1 .. 3]]
val it : Cons = [(k:@a v:1), (k:@a v:2), (k:@a v:3), (k:@b v:1), (k:@b v:2), (k:@b v:3)]
umu:3>リスト内包表記の高度な使いかたは データベースの例 を参照してください。
8. ラムダ式と関数
8.1. ラムダ式
umu:1> { x y -> x + y }
fun it = #<{ x y -> (+ x y) }>
umu:2> it 3 4
val it : Int = 7
umu:3>umu:1> { x y -> x + y } 3
fun it = #<{ y -> (+ x y) }>
umu:2> it 4
val it : Int = 7
umu:3>umu:1> { (x, y) -> 3 + 4 }
fun it = #<{ %a1 : Product -> %LET { %VAL x = (%a1)$1 %VAL y = (%a1)$2 %IN (+ 3 4) } }>
umu:2> it (3, 4)
val it : Int = 7
umu:3>8.2. 関数定義
8.2.1. 単純な関数
宣言 val は値(value)を識別子(identifier)に束縛(bind)します。
ここで、その値は関数オブジェクト(function object)です。
umu:1> val add = { x y -> x + y }
fun add = #<{ x y -> (+ x y) }>
umu:2> add 3 4
val it : Int = 7
umu:3>宣言 fun は関数オブジェクトの束縛に関する構文糖(syntactic sugar)です。
umu:1> fun add' = x y -> x + y
fun add' = #<add': { x y -> (+ x y) }>
umu:2> add' 3 4
val it : Int = 7
umu:3>umu:1> fun add'' = (x, y) -> x + y
fun add'' = #<add'': { %a1 : Product
**> %LET { %VAL x = (%a1)$1 %VAL y = (%a1)$2 %IN (+ x y) }
}>
umu:2> add'' (3, 4)
val it : Int = 7
umu:3>8.2.2. 再帰関数
再帰関数(recursive function)は宣言 fun rec で定義します。
umu:1> fun rec factorial = x -> ( # 'umu/example/factorial.umu'をコピー&ペースト
umu:2* if x <= 1 then
umu:3* 1
umu:4* else
umu:5* x * factorial (x - 1)
umu:6* )
fun factorial = #<factorial: { x -> (%IF (<= x 1) %THEN 1 %ELSE (* x (factorial (- x 1)))) }>
umu:7> factorial 3
val it : Int = 6
umu:8>9. メッセージと送信式
9.1. メッセージ
メッセージは以下のように分類されます。
-
インスタンスメッセージ
-
単純インスタンスメッセージ
-
単項インスタンスメッセージ
-
[例] Int#to-s : String
-
[例] Bool#not : Bool
-
[例] List#join : String
-
-
二項インスタンスメッセージ
-
[例] Int#+ : Int → Int
-
[例] Int#to : Int → Interval
-
[例] String#^ : String → String
-
[例] List#cons : Top → List
-
[例] List#join-by : String → String
-
[例] Fun#apply : Top → Top
-
-
多項インスタンスメッセージ
-
[例] Int#to-by : Int → Int → Interval
-
[例] List#foldr : Top → Fun → Top
-
[例] Fun#apply-binary : Top → Top → Top
-
[例] Fun#apply-nary : Top → Top → Morph → Top
-
-
-
キーワードインスタンスメッセージ
-
[例] Int#(to:Int) → Interval
-
[例] Int#(to:Int by:Int) → Interval
-
[例] List#(join:String) → String
-
-
-
クラスメッセージ
-
単純クラスメッセージ
-
[例] &Bool.true : Bool
-
[例] &Float.nan : Float
-
[例] &Some.make : Top → Some
-
[例] &Datum.make : Symbol → Top → Datum
-
[例] &List.cons : Top → Morph → Morph
-
[例] &Interval.make : Int → Int → Interval
-
[例] &Interval.make-by : Int → Int → Int → Interval
-
-
キーワードクラスメッセージ
-
[例] &Datum.(tag:Symbol contents:Top) → Datum
-
[例] &List.(head:Top tail:Morph) → Morph
-
[例] &Interval.(from:Int to:Int) → Interval
-
[例] &Interval.(from:Int to:Int by:Int) → Interval
-
-
9.2. インスタンスメッセージとクラスメッセージ
インスタンスメッセージは普通のメッセージです。
クラスメッセージはクラス式 &Foo で生成されるクラスオブジェクトへのメッセージです。
これは多くの場合、以下の目的で用いられます。
-
あるクラスからインスタンスを生成するオブジェクト構成子(object constructor)を提供
-
非オブジェクト指向な手続き型言語/関数型言語におけるライブラリ関数やシステムコールを提供
[!NOTE] 現在、JavaやRubyで見かけるインスタンス生成の予約語
newは、定義されていますが使われていません。 将来、クラスのユーザー定義機能が提供される時、new Foo xという文法で使われるようになる予定です。
9.3. 単純メッセージとキーワードメッセージ
単純メッセージはカリー化されるメッセージであり、オブジェクト指向と関数型を混在したプログラミングスタイルに適しています。
キーワードメッセージはカリー化されないメッセージであり、複雑な引数を伴うメッセージでは単純メッセージよりも可読性が優れています。
9.4. 関数適用とメッセージ送信
umu:1> 3 + 4 # 中置演算子式
val it : Int = 7
umu:2> (+) 3 4 # 関数オブジェクトとしての中置演算子
val it : Int = 7
umu:3> ((+) 3) 4 # 第一引数の部分適用
val it : Int = 7
umu:4> (+ 4) 3 # 第二引数の部分適用
val it : Int = 7umu:5> 3.(+ 4) # 二項メッセージ '+4' を整数オブジェクト 3 へ送信
val it : Int = 7
umu:6> 3.+ 4 # カッコは省略できます
val it : Int = 7
umu:7> (3.+) 4 # 二項メッセージのキーワード '+' だけを送信
val it : Int = 7
umu:8> &(+) 3 4 # 関数オブジェクトとしての二項メッセージ
val it : Int = 7
umu:9> (&(+) 3) 4 # 第一引数の部分適用
val it : Int = 7umu:10> (+).apply-binary 3 4 # 関数オブジェクトに適用メッセージを送信
val it : Int = 7
umu:11> (+).[3, 4] # もう一つの適用メッセージ記法(構文糖)
val it : Int = 79.5. メッセージチェイン、パイプライン適用そして関数合成
ここで解説するプログラム表現の考察は、edvakfさんのブログ記事: PythonでもRubyみたいに配列をメソッドチェーンでつなげたい を出発点としています。
9.5.1. メッセージチェイン
オブジェクト指向プログラミングの標準的なスタイルであり、 複数のメッセージを送信式で繋ぐ(chain)ことによって、 左から右へと流れるようなコードが書けます。
umu:1> [1, 4, 3, 2]
val it : Cons = [1, 4, 3, 2]
umu:2> [1, 4, 3, 2].sort
val it : Cons = [1, 2, 3, 4]
umu:3> [1, 4, 3, 2].sort.reverse
val it : Cons = [4, 3, 2, 1]
umu:4> [1, 4, 3, 2].sort.reverse.map to-s
val it : Cons = ["4", "3", "2", "1"]
umu:5> [1, 4, 3, 2].sort.reverse.map to-s.join-by "-"
val it : String = "4-3-2-1"
umu:6>9.5.2. パイプライン適用
F#, Ocaml, Scala, Elixir のように …
関数型プログラミングのスタイルの一つであり、
一つの式と複数の関数をパイプライン演算子 |> で連結(concatenate)することによって、
左から右へと流れるようなコードが書けます。
umu:1> [1, 4, 3, 2] |> sort |> reverse |> map to-s |> join-by "-"
val it : String = "4-3-2-1"
umu:2>9.5.3. もう一つのパイプライン適用
(2) と似ていますが、こちらは値がパイプラインを右から左へと流れます。
このスタイルは、あまりに過剰なカッコに疲れ果てている全世界のプログラマーにとって、救いの手となるでしょう。
特に Haskell だとパイプライン演算子は標準演算子 $ として定義され、好んで広く使われています。
umu:1> join-by "-" <| map to-s <| reverse <| sort [1, 4, 3, 2]
val it : String = "4-3-2-1"
umu:2>9.5.4. 関数合成
ここまで述べたメッセージチェインやパイプライン適用といったプログラミング技法よりも更に視点を上に向け、 設計技法として「コードの部品化と再利用」を推進するのが関数合成です。
以下の例では、4個の部品 sort、 reverse、 map to-s そして`join-by "-"` について、
関数合成演算子 >> で左から右へと合成し、完成した関数オブジェクトを f として定義しています。
umu:1> val f = sort >> reverse >> map to-s >> join-by "-"
fun f = #<{ %x -> (%x |> sort |> reverse |> (map to-s) |> (join-by "-")) }>
umu:2> f [1, 4, 3, 2]
val it : String = "4-3-2-1"
umu:39.5.5. もう一つの関数合成
(3) と似ていますが、こちらは関数合成演算子 << で部品を右から左へ合成します。
Haskell だと関数合成演算子は標準演算子 . として定義され、
このスタイルがポイントフリースタイル(point free style)と命名されるほど広く知られ、
好んで使われています。
umu:1> val f = join-by "-" << map to-s << reverse << sort
fun f = #<{ %x -> (%x |> sort |> reverse |> (map to-s) |> (join-by "-")) }>
umu:2> f [1, 4, 3, 2]
val it : String = "4-3-2-1"
umu:3>9.5.6. 伝統的な入れ子になった関数適用
Lisp, Python, Pascal, Fortran のように …
科学技術計算のような数値関数ライブラリであれば、あえて伝統的なスタイルを採用することも検討すべきでしょう。
umu:1> join-by "-" (map to-s (reverse (sort [1, 4, 3, 2])))
val it : String = "4-3-2-1"
umu:2>10. パターン(未)
11. 分岐式(未)
11.1. if式
11.2. cond式
11.3. case式
12. 遅延評価とストリーム(未)
13. 入出力(未)
14. ファイルとディレクトリ(未)
15. リファレンス
リファレンス(reference, 参照)は可変(mutable)なメモリ領域を表現するオブジェクトです。 ここまで、ある変数に値を割り当てる操作を束縛(binding)と呼んできました。 これは関数型言語では一般的ですが、手続き型言語では以下に示す別の視点で変数に値を割り当てます。
-
「変数」とは、メモリ領域へ紐付けた名札(label, ラベル)である
-
「変数の値」とは、変数で指定されるメモリ領域から保存されている値を読み出す操作である
-
「変数に値を割り当てる」とは、値を変数で指定されるメモリ領域へ書き込む操作である
この仕組みは破壊的代入(destructive assignment)と呼ばれています。
この破壊的代入をオブジェクト指向で実装したものがリファンスオブジェクトであり、 以下のメッセージに対して応答します。
-
&Ref.make : Top → Ref
引数を初期値とするメモリ領域を1つ確保し、それをリファレンスで返す
-
Ref#peek! : Top
リファレンスが持つメモリ領域に保存されている値を読み出し、それを返す
-
Ref#poke! : Top → Unit
引数の値をリファレンスが持つメモリ領域へ書き込む
umu:1> val rx = &Ref.make 3 # 3 を初期値とするリファレンスを定義
val rx : Ref = #Ref(3)
umu:2> rx.peek! # リファレンスから現在の値を読み出す ==> 3
val it : Int = 3
umu:3> rx.peek!.+ 4 |> rx.poke! # 現在の値に 4 を足し、その結果をリファレンスへ書き込む
val it : Unit = ()
umu:4> rx.peek! # リファレンスから現在の値を読み出す ==> 7
val it : Int = 7
umu:5>単純な機能(service)ですが、冗長です。
そこで、これらのメッセージを抽象化した標準関数 ref および標準演算子 !! と := を提供します。
umu:1> val rx = ref 3 # 3 を初期値とするリファレンスを定義
val rx : Ref = #Ref(3)
umu:2> !!rx # リファレンスから現在の値を読み出す ==> 3
val it : Int = 3
umu:3> rx := !!rx + 4 # 現在の値に 4 を足し、その結果をリファレンスへ書き込む
val it : Unit = ()
umu:4> !!rx # リファレンスから現在の値を読み出す ==> 7
val it : Int = 7
umu:5>umu:1> val rx = ref 3 # 3 を初期値とするリファレンス rx を定義
val rx : Ref = #Ref(3)
umu:2> val ry = ref 4 # 4 を初期値とするリファレンス ry を定義
val ry : Ref = #Ref(4)
umu:3> !!rx + !!ry # リファレンス rx から読み出した値と同 ry から読み出した値を足す
val it : Int = 7
umu:4>破壊的代入に興味を持たれたなら、Lisp を使ったコンピュータサイエンスの教科書である
SICPの
節 3.1 代入と局所状態
を参照してください。
またリファレンスを使うよう書き改めたコードが
SICPの例
にあります。